Lecture 11: Finishing Locks; Vectors
COSC 273: Parallel and Distributed Computing
Spring 2023
Last Time: Fair Locks, More Threads
Lamport’s Bakery Algorithm
Fields:
-
boolean[] flag-
flag[i] == trueindicatesiwould like enter CS
-
-
int[] label-
label[i]indicates “ticket” number held byi
-
Initialization:
- set all
flag[i] = false,label[i] = 0
Locking
Locking Method:
public void lock () {
int i = ThreadID.get();
flag[i] = true;
label[i] = max(label[0], ..., label[n-1]) + 1;
while (!hasPriority(i)) {} // wait
}
The method hasPriority(i) returns true if and only if there is no k such that
-
flag[k] == trueand - either
label[k] < label[i]orlabel[k] == label[i]andk < i
Unlocking
Just lower your flag:
public void unlock() {
flag[ThreadID.get()] = false;
}
Bakery Algorithm is Deadlock-Free
public void lock () {
int i = ThreadID.get();
flag[i] = true;
label[i] = max(label[0], ..., label[n-1]) + 1;
while (!hasPriority(i)) {} // wait
}
Why?
First-come-first-served (FCFS)
- If: $A$ writes to
labelbefore $B$ callslock(), - Then: $A$ enters CS before $B$.
public void lock () {
int i = ThreadID.get();
flag[i] = true;
label[i] = max(label[0], ..., label[n-1]) + 1;
while (!hasPriority(i)) {} // wait
}
Why?
Bakery Algorithm is Starvation-Free
Why?
Thread i calls lock():
-
iwriteslabel[i] - By FCFS, subsequent calls to
lock()byj != ihave lower priority - By deadlock-freedom every
kahead ofieventually releases lock
So:
-
ieventually served
Bakery Algorithm Satisfies MutEx
public void lock () {
int i = ThreadID.get();
flag[i] = true;
label[i] = max(label[0], ..., label[n-1]) + 1;
while (!hasPriority(i)) {} // wait
}
Suppose not:
- $A$ and $B$ concurrently in CS
- Assume: $(\mathrm{label}(A), A) < (\mathrm{label}(B), B)$
Proof (Continued)
Since $B$ entered CS:
- Must have read
- $(\mathrm{label}(B), B) < (\mathrm{label}(A), A)$, or
- $\mathrm{flag}[A] == \mathrm{false}$
Why can’t 1 happen?
Compare Timelines!
Conclusion
Lamport’s Bakery Algorithm:
- Works for any number of threads
- Satisfies MutEx and starvation-freedom
Is the bakery algorithm practical?
Two Issues:
- For $n$ threads, need arrays of size $n$
-
hasPrioritymethod is costly - what if we don’t know how many threads?
-
- Assume threads have sequential IDs
0, 1,...- not the case with Java!
- thread IDs are essentially random
longvalues
Homework 2 will have questions that address these issues.
Remarkably
We cannot do better!
- If $n$ threads want to achieve mutual exclusion + deadlock-freedom, must have $n$ read/write registers (variables)
Lower Bound Argument Sketch
Consider $n$ threads, $m < n$ shared memory locations
- fix some mutex protocol
A covering state is a step in an execution in which:
- Each thread’s next step is a
writeoperation - Each thread’s view is consistent with CS unoccupied
- Each memory location has a thread about to write to it
Claim
If an execution reaches a covering state, then the protocol does not satisfy mutual exclusion.
Why?
Finishing Lower Bound Argument
Show. Any protocol with $m < n$ memory locations attains a covering state in some execution.
- Read AMP Section 2.9 for details
Consequences:
-
If only synchronization primitives are
read/writethen $n$ shared memory locations are necessary for deadlock-free mutual exclusion with $n$ threads- Bakery algorithm is nearly optimal (memory of $2n$)
- Led to development of stronger primitives
A Way Around the Bound
-
Argument relies crucially on fact that the only atomic operations are
readandwrite -
Modern computers offer more powerful atomic operations
-
In Java,
AtomicIntegerclass-
getAndIncrement()is supported atomic operation
-
Homework 2 Use AtomicIntegers to get a cleaner and more efficient realization of Lamport’s bakery idea.
Changing Gears
Performance, Again
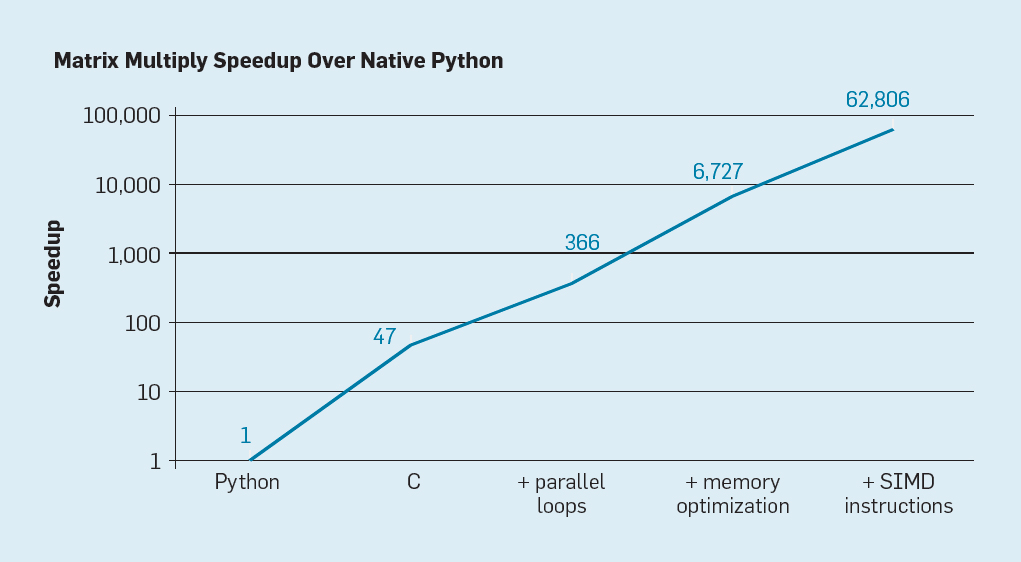
More Powerful Hardware
In Java, int and float values are 32 bits long
In modern CPUs, registers are larger
- my computer: 256 bit registers
Naive Operations
int a = 573842;
int b = 3847253;
int c = a + b;
SIMD Parallel Operations
int a1 = 573842;
int b1 = 3847253;
int c1 = a1 + b1;
int a2 = 38657548;
int b2 = 438573;
int c2 = a2 + b2;
Naive Loops
int[] a = new int[n];
int[] b = new int[n];
int[] c = new int[n];
for (int i = 0; i < n; i++) {
c[i] = a[i] + b[i];
}
Using Full Power
Suppose we can load step values into each register
int[] a = new int[n];
int[] b = new int[n];
int[] c = new int[n];
for (int i = 0; i < n; i += step) {
c[i] = a[i] + b[i];
c[i+1] = a[i+1] + b[i+1];
...
c[i+step-1] = a[i+step-1] + b[i+step-1]
}
Java Vector API
Allows us to specify Vector objects
-
Vectoris like fixed-size array - tune
Vector(bit) size to same as hardware registers - perform elementary operations on entire vectors
Notes:
- Vector API in Java 19, available as “incubator”
- Many optimizations already done (without
Vector)
Example
Find entry-wise minimum of arrays:
VectorSpecies<Float> SPECIES = FloatVector.SPECIES_PREFERRED;
...
public static float[] vectorMax(float[] a, float[] b) {
float[] c = new float[a.length];
int step = SPECIES.length();
int bound = SPECIES.loopBound(a.length);
...
}
Example Continued
Find entry-wise minimum of arrays:
...
int i = 0;
for (; i < bound; i += step) {
var va = FloatVector.fromArray(SPECIES, a, i);
var vb = FloatVector.fromArray(SPECIES, b, i);
var vc = va.max(vb);
vc.intoArray(c, i);
}
for (; i < a.length; i++) {
c[i] = Math.max(a[i], b[i]);
}
return c;
}
Speedup for Me
The FloatVector has 8 lanes.
Computing max array with simple methods...
That took 927 ms.
Computing max array with vector methods...
That took 572 ms.
The arrays are equal!
Next Lab
Use Vector operations to speed up programs!