Lecture 14: More Locking Strategies
Overview
- Review of TAS and TTAS
- Backing Off
- Queue Based Locks
Last Time
The Test-and-set (TAS) Lock:
public class TASLock {
AtomicBoolean isLocked = new AtomicBoolean(false);
public void lock () {
while (isLocked.getAndSet(true)) {}
}
public void unlock () {
isLocked.set(false);
}
}
Performance of TAS
Decreases with number of processors
- From Remus and Romulus (1M lock accesses):
n elapsed time (ms)
1 109
2 200
3 492
4 494
5 576
6 804
7 796
8 1001
9 1130
10 1128
11 1123
12 1260
13 1320
14 1476
15 1610
16 1646
17 1594
18 1198
19 1755
20 1139
21 1940
22 2033
23 2133
24 2258
25 2125
26 2578
27 2211
28 2432
29 2188
30 2663
31 2579
Doing same number of ops takes 25 times as long on 31 threads as on 1 thread!
One Problem with TAS
public class TASLock {
AtomicBoolean isLocked = new AtomicBoolean(false);
public void lock () {
while (isLocked.getAndSet(true)) {}
}
public void unlock () {
isLocked.set(false);
}
}
Each thread calls getAndSet constantly!
- more complex atomic primitive operations are more costly
Another Approach
Only try to getAndSet if previously saw lock was unlocked
- the Test-and-test-and-set (TTAS) lock:
public void lock () {
while (true) {
while (isLocked.get()) {};
if (!isLocked.getAndSet(true)) {
return;
}
}
}
- Less frequent
getAndSet$\implies$ better performance?
TTAS Lock Performance
Same test as before on Remus and Romulus (1M accesses):
n elapsed time (ms)
1 108
2 202
3 206
4 212
5 253
6 237
7 218
8 242
9 275
10 250
11 214
12 239
13 216
14 265
15 219
16 283
17 266
18 287
19 279
20 286
21 231
22 294
23 300
24 243
25 293
26 303
27 300
28 294
29 302
30 303
31 305
32 309
Now: performance with 32 threads is less than 3 times slower than without contention!
- That is about 8 times faster than TAS lock!
The Moral
- Read more, write less!
- reading atomic variables is more efficient than writing
- this is especially true when there is a lot of contention
Yet Another Approach
Backing off under contention
public void lock () {
while (true) {
while (isLocked.get()) {};
if (!isLocked.getAndSet(true)) {
return;
}
}
}
- If we hit
if (...)but fail to acquire lock, there are other threads attempting to acquire lock- contention detected at this point
- So: we could wait
Exponential Backoff
Store:
-
MIN_DELAY,MAX_DELAY(constants) -
limitinitialized toMIN_DELAY
When contention detected:
- Pick random
delaybetween0andlimit - Update
limit = Math.min(2 * limit, MAX_DELAY) - Wait
delaytime before attempting to acquire lock again
Illustration
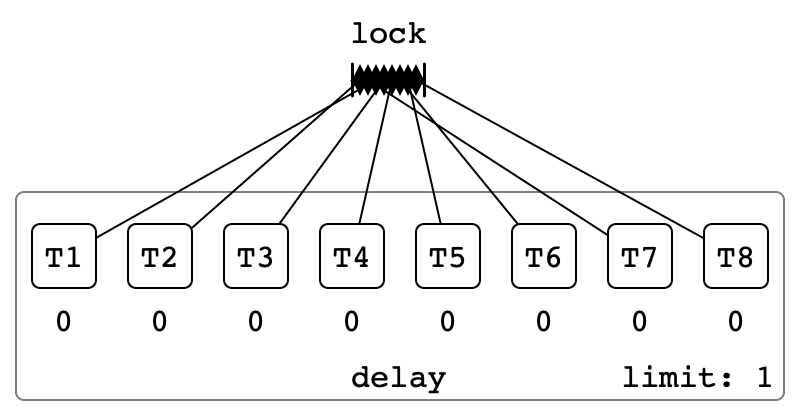
Contention Detected
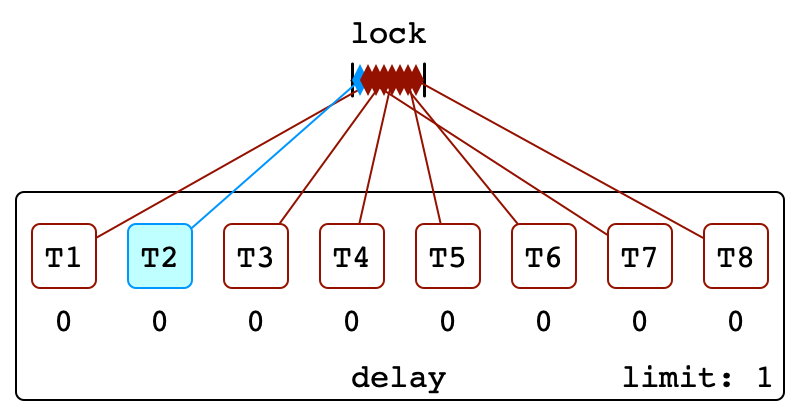
First Backoff
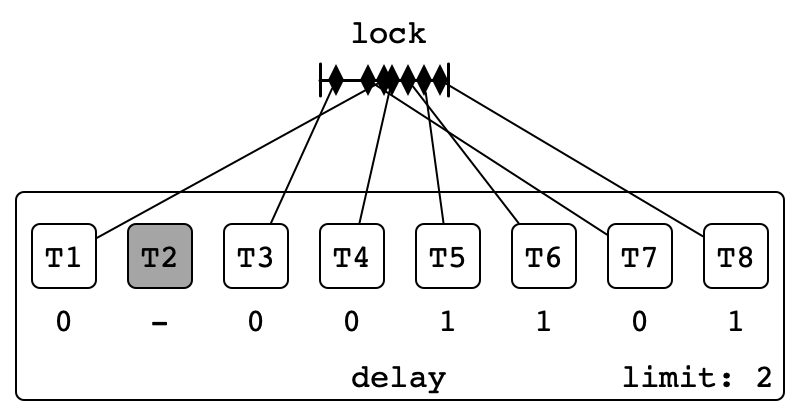
More Contention
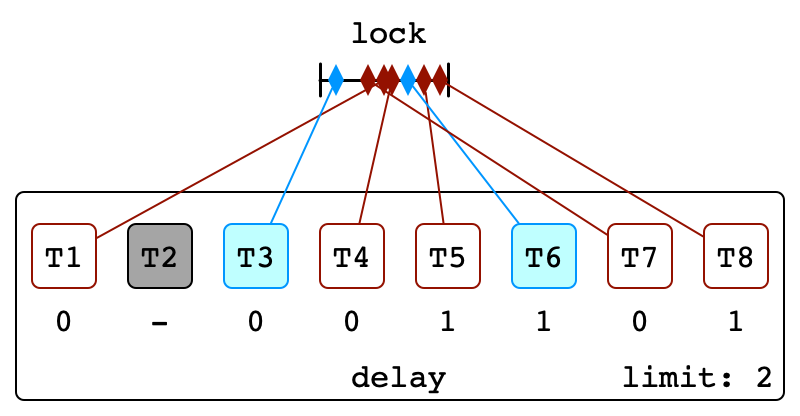
Second Backoff
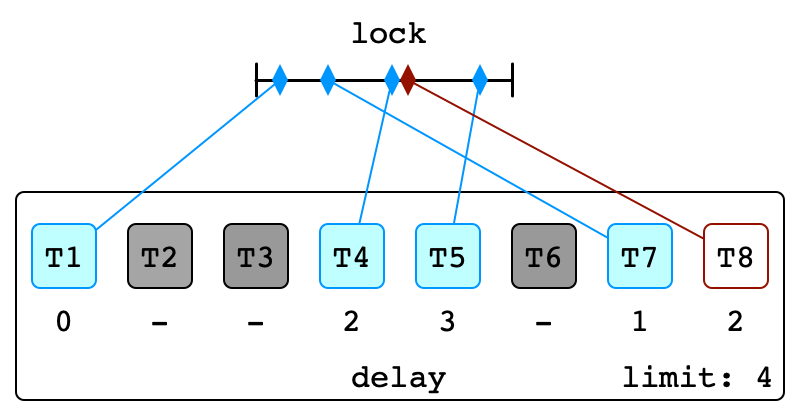
Final Backoff
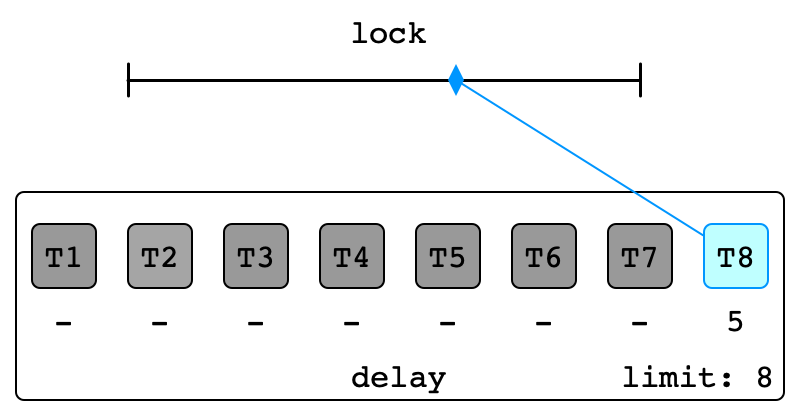
Result of Exponential Backoff
- Spread out attempts to acquire lock
- more contention $\implies$ larger
delay - $\implies$ each attempt more likely to succeed
- more contention $\implies$ larger
- Waiting threads don’t use (as many) computer resources
- Locked resource may be under-utilized
Implementing Exponential Backoff
Is it practical?
n elapsed time (ms)
1 148
2 234
3 250
4 226
5 216
6 230
7 255
8 267
9 262
10 269
11 271
12 276
13 265
14 298
15 289
16 267
17 296
18 292
19 308
20 280
21 290
22 302
23 261
24 304
25 313
26 317
27 317
28 331
29 322
30 313
31 315
32 314
Not better than TTAS for tested parameters.
Technical Problem
Textbook Backoff uses Thread.sleep(...)
-
sleeptells OS scheduler not to schedule thread for a while- doesn’t use resources like
while (true) {};
- doesn’t use resources like
- Minimum
sleepdelay is 1 ms - This is MILLIONS of CPU cycles!
- way too long to help with high contention/small tasks!
- My wasteful implementation uses “busy waiting”:
private void spin (long delay) {
long start = System.nanoTime();
long cur = System.nanoTime();
while (cur - start < delay) {
cur = System.nanoTime();
};
}
The Moral
Exponential backoff is:
- A useful strategy in a variety of contexts
- frequently used in network protocols
- Probably not the best strategy for most of our locking needs
A Goal
So far:
TASLockTTASLockBackoffLock
are deadlock-free, but not starvation free!
Question. How to achieve starvation freedom?
Queueing Lock Strategy
Represent threads waiting for lock as a queue
- linked list representation of queue
- each thread has associated node
- node stores boolean value:
-
trueI want/have lock -
falseI don’t want/have lock
-
- thread also stores predecessor node
- list initialized with a single node
-
tailnode storingfalse
-
Initial Configuration
Thread A Acquires Lock
Thread B Calls lock()
Thread A Releases Lock
Thread B Acquires Lock
Technical Challenge
We need a Node for each thread!
- Don’t know number of threads in advance!