Lab Week 04: Cache Locality
Outline
- Cache Hierarchies
- Activity: Effects on Performance
- Improving Performance
- Relation to Lab 02: Computing Shortcuts
Cache Hierarchies
So Far
We’ve assumed:
- Processors read from and write to registers (variables)
- These actions are
- atomic
- efficient (effectively instantaneous)
Idealized Picture
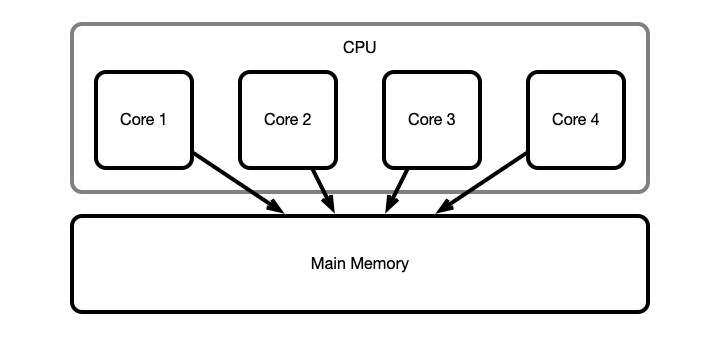
Unfortunately
Computer architechture is not so simple!
- Accessing main memory (RAM) directly is costly
- can be 100s of CPU cycles to read/write a value!
- Use hierarchy of smaller, faster memory locations:
- caching
- different levels of cache: L1, L2, L3
- cache memory integrated into CPU $\implies$ faster access
A More Accurate Picture
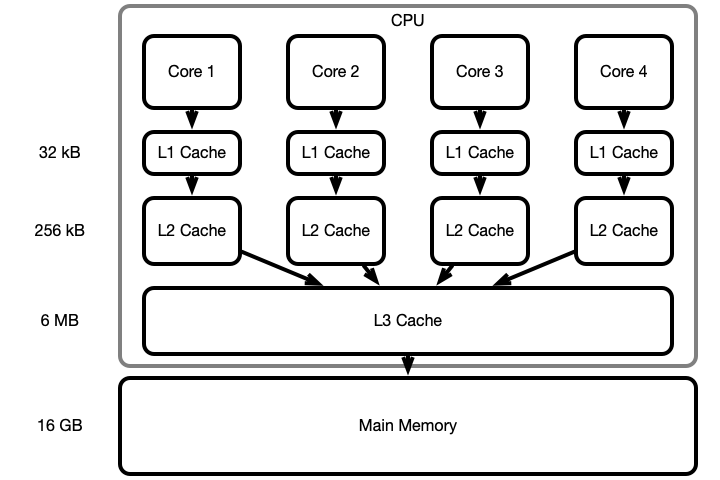
How Memory is Accessed
When reading or writing:
- Look for symbol (variable) successively deeper memory locations
- L1, L2, L3, main memory
- Fetch symbol/value into L1 cache and do manipulations here
- When a cache becomes full, push its contents to a deeper level
- Periodically push changes down the heirarchy
Memory Access Illustrated
Why Is Caching Done? Efficiency!
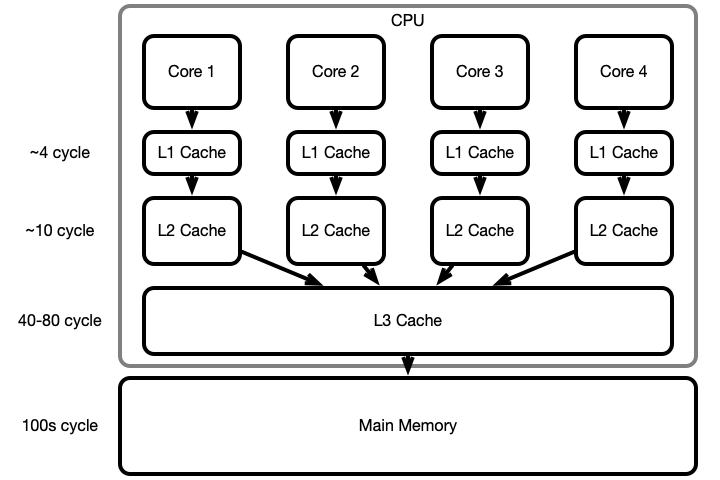
Why Caching Is Efficient
Heuristic:
- Most programs read/write to a relatively small number of memory locations often
- These values remain in low levels of the hierarchy
- Most commonly performed operation are performed efficiently
Why Caching is Problematic
Cache (in)consistency
- L1, L2 cache for each core
- Multiple cores modify same variable concurrently
- Only version stored in local cache modified quickly
- Same variable has multiple values simultaneously!
Takes time to propogate changes to values
- Shared changes only occur periodically!
Counter Example Revisited
Previously, we saw
- 2 threads simultaneously increment
Counterobject - Result: ~1/2 of increments seemed to be performed
Makes sense with cache
- Each thread incremented variable in its local L1 cache
- Local and shared values only periodically compared for consistency
- Values may still be equal due to parallel increment!
Prefetching
Heuristic:
- Most programs access memory linearly (in order)
- If I access
arr[i], likely next access isarr[i+1]- or at least
arr[i+c]for some smallc
- or at least
Fetch many values from higher levels at a time
- If
arr[i]is fetched from high level, also fetcharr[i+1]...arr[i+c] - Don’t wait for request for those memory locations
- Often, variables are already in low-level cache when needed!
Moral
- Your computer expects your program to access memory in order
- When your program does access memory in order, it often will run more efficiently
- effect may be large!
So write write programs that access memory linearly!
Example: Reading from an Array
-
float[] arra reasonably large array -
int[] indicesindices ofarrto be accessedfloat sum = 0; for (int i : indices) sum += arr[i]; - this may run much faster for
indices = {0, 1, 2, 3, ...}than
indices = {2743, 1, 9932, 4952,...}How much faster?
Effects on Single-Core Performance
Activity
Investigate how much access order effects efficiency of a program
- Fix number of accesses (~1B)
- Vary size of array being accessed
- larger arrays cannot fit in low level cache
- Compare linear access with random access
Questions
Comparison of Linear vs Random Access Runtime?
How did array size affect run-time?
Effeciency of Re-sorting Random Access Array?
Improving Performance
Moral
If access pattern
- is known in advance and
- is non-linear
may be more efficient to reorganize data structure so that access pattern is linear
Computing Shortcuts
Array Access
Heuristic:
- Array elements stored sequentially in memory
2D Array Access: Rows before Cols
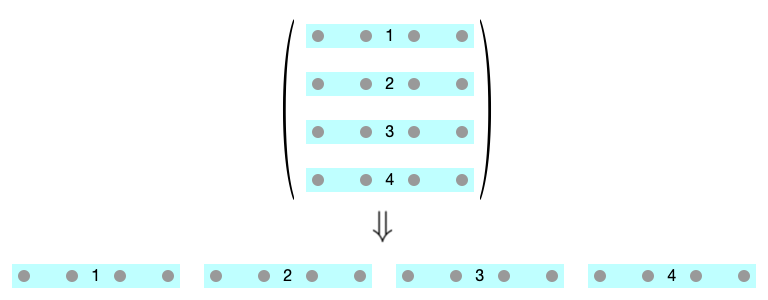
2D Array Access: Cols before Rows
Access Pattern for Main Loop
for (int i = 0; i < size; ++i) {
for (int j = 0; j < size; ++j) {
float min = Float.MAX_VALUE;
for (int k = 0; k < size; ++k) {
float x = matrix[i][k];
float y = matrix[k][j];
float z = x + y;
if (z < min) {
min = z;
}
}
shortcuts[i][j] = min;
}
}
Result of Optimizing Access Pattern
|------|------------------|-------------|------------------|---------|
| size | avg runtime (ms) | improvement | iteration per us | passed? |
|------|------------------|-------------|------------------|---------|
| 128 | 10 | 1.07 | 201 | yes |
| 256 | 42 | 1.23 | 396 | yes |
| 512 | 317 | 0.75 | 422 | yes |
| 1024 | 680 | 6.91 | 1578 | yes |
| 2048 | 6249 | 9.98 | 1374 | yes |
| 4096 | 57592 | 11.05 | 1193 | yes |
|------|------------------|-------------|------------------|---------|
Up to 11x speedup, before multithreading
Combining Multithreading with Cache Locality Optimization
|------|------------------|-------------|------------------|---------|
| size | avg runtime (ms) | improvement | iteration per us | passed? |
|------|------------------|-------------|------------------|---------|
| 128 | 24 | 0.80 | 86 | yes |
| 256 | 6 | 18.94 | 2623 | yes |
| 512 | 21 | 13.11 | 6132 | yes |
| 1024 | 157 | 31.70 | 6828 | yes |
| 2048 | 1123 | 55.11 | 7647 | yes |
|------|------------------|-------------|------------------|---------|
Even Better Results on Romulus/Remus
|------|------------------|-------------|------------------|---------|
| size | avg runtime (ms) | improvement | iteration per us | passed? |
|------|------------------|-------------|------------------|---------|
| 128 | 310 | 0.04 | 6 | yes |
| 256 | 52 | 1.14 | 317 | yes |
| 512 | 18 | 14.71 | 7105 | yes |
| 1024 | 87 | 57.84 | 12257 | yes |
| 2048 | 464 | 146.15 | 18478 | yes |
| 4096 | 3120 | 190.11 | 22020 | yes |
|------|------------------|-------------|------------------|---------|